[New post] PDF Table to CSV- Extract Tables/Table Data from PDFs & Convert to CSV
Matteo posted: " Looking to extract tables from PDFs and convert them to CSV format? Try Nanonets PDF table extractor to extract tabular data for free and convert them to CSVs. Tables are one of the most loved data formats! They help us represent and an"
Looking to extract tables from PDFs and convert them to CSV format?Try Nanonets PDF table extractor to extract tabular data for free and convert them to CSVs.
Tables are one of the most loved data formats! They help us represent and analyze data quickly and intuitively. Today, almost every business utilizes tables on various data formats like PDFs, images, emails to represent different types of information. Some of them include financial data, daily operations metrics, accounting data, and many more.
PDF table to CSV
One of the significant drawbacks of using this format is that none of this data is searchable, as most are non-electronic documents. Therefore, several businesses and organizations rely on modern technologies to extract data from tables and to convert them into an editable format. This process is usually called information extraction, and in our case, since we're extracting tables from documents, we can specifically call this table extraction. This process uses different algorithms and workflows to achieve state-of-the-art performance; however, techniques like OCR and deep learning are easily doable with the present infrastructure and computational power in use today.
Even though the extracted data is stored in different formats one of the frequently used formats is the Comma Separated Value or CSV in short. This is widely used because it can be easily imported and exported directly into many software and computer programs.
In this blog, we'll look at different ways of extracting PDF tables into CSV format. We'll discuss and implement various techniques utilized in the process and create a workflow that'll help us automate data extraction from tables to CSVs. Following are the table of contents.
Need a free online OCR to extract and convert tables from PDFs, images to CSV? Check out Nanonets and build custom OCR models and extract/convert tables to CSVs for free!
What is PDF table extraction and why is it important?
PDF format is widely used by almost every organization or business. It is because the PDF format is well organized and highly secure. In PDFs, we often use tables to present specific data, however as discussed, we cannot search through PDFs that are non-electronically generated, which means when there are images or any scanned data. Therefore, we extract data from these PDFs using information extraction techniques and store them in an editable and searchable way, as this information is used to help businesses generate analyses.
When using information extraction algorithms on PDFs, one can easily extract standard text containing headings and paragraphs using OCR but extracting tables is quite challenging as the number of rows and columns is not always generic. Also, different parameters are included here, such as rows, columns, cells data, padding, empty cells, and many more. Therefore, traditional OCR will not work here; instead, we must rely on different table extraction algorithms to extract data from tables inside PDFs.
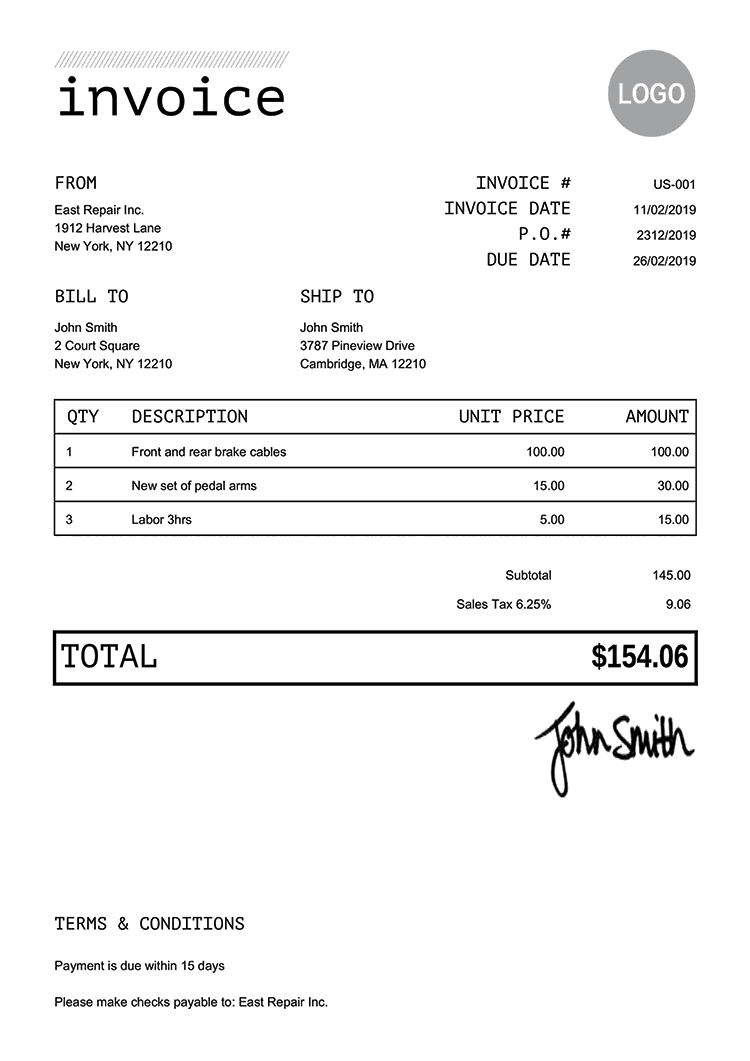
Here's an example; the following is a screenshot of a page from a PDF file with a table; when using traditional OCR (Tesseract), all the text is extracted with high accuracy, but table extraction is not that great.
Extract Table from PDFs to CSV
invoice LOGO FROM INVOICE # US-001 East Repair Inc. INVOICE DATE 11/02/2019 1912 Harvest Lane New York, NY 12210 P.O.# 2312/2019 DUE DATE 26/02/2019 BILL TO SHIP TO John Smith John Smith 2 Court Square 3787 Pineview Drive New York, NY 12210 Cambridge, MA 12210 QTY DESCRIPTION UNIT PRICE AMOUNT Front and rear brake cables 100.00 100.00 2 New set of pedal arms 15.00 30.00 3 Labor 3hrs 5.00 15.00 Subtotal 145.00 Sales Tax 6.25% 9.06 TOTAL $154.06 An ShiR TERMS & CONDITIONS Payment is due within 15 days Please make checks payable to East Repair Inc.
Therefore, when converting tabular data from CSV, we must rely on other technologies depending on how the data is organized. Usually, we find three types of PDFs:
Electronic PDFs: PDFs exported from software such as Google Docs, MS Word, or Adobe.
Image-based PDFs: PDF containing text within images (when the text is scanned through mobile devices and added to PDFs).
Mixed PDFs: PDFs that have both searchable text and scanned images or text.
We could rely on simple programming languages and frameworks such as Python and Java for the first case. At the same time, for the PDFs that are non-electronically generated, we'll need to utilize Computer Vision techniques with OCR and deep learning. However, these algorithms might not be the same for all the table extraction algorithms, and they'll need to change depending on the type of data to achieve higher accuracy. Additionally, in some cases, NLP (Natural Language Processing) is also utilized to understand the data inside tables and extract them. We'll discuss these techniques more in the next few sections.
Now, let's talk about some of the formats where we can save the information that's extracted from the tables. The main goal here is to choose a format that'll easily allow us to put the extracted data into tables and also allows us to load it into different programming frameworks. This is where CSV comes into the picture.
In ordinary circumstances, a CSV file is used to transfer data from one application to another. A CSV file stores data, both numbers, and text, in plain text by way of explanation. As you may know, plain text compresses the information and allows text formatting.
Customarily, all fields are separated by commas, while an elaborate line of characters separates all records. In Excel sheets, all fields that have a comma are embedded inside double quotes, commonly known as text qualifiers, i.e., one single cell with one, two, and three will be captured as "one, two, and three."
Need a free online OCR to extract and convert tables from PDFs, images to CSV? Check out Nanonets and build custom OCR models and extract/convert tables to CSVs for free!
In this section, let's look at some of the frequent use cases on how converting a PDF table to CSV will be helpful for business.
Automating Data Entry for Financial Documents: Several businesses deal with lots of financial documents. In some cases, they rely on manual data entry where operators manually convert scanned data into digital format. However, this process is not efficient as it's expensive and error-prone. Therefore, relying on an automated solution, where a single person could capture images and upload them into an OCR-based tech could get work done more efficiently with higher accuracy. Also, by using these algorithms we can also classify the documents based on the types of content and automate data entry.
Table data from PDF to CSV
Invoice Automation: We receive invoices for every transaction we make, whether it is for the service we provide or for the services we utilize. Keeping track of all the invoices is hard, and people manually enter expenses in different software to track their money. Now, one might wonder how exporting PDF tables to CSV can help solve this problem. As we know, most of the invoices are usually sent through emails or handed over as hard copies; therefore, table extraction here can help us track all the expenses from the invoices to maintain a robust database for future analysis.
These are some of the frequently seen use-cases, however, some industries like manufacturing, construction, medical largely rely on table extraction algorithms for organising their data efficiently.
We've learned a lot about PDF table extraction to CSV so far. In this section, we'll write simple python scripts that'll help us extract tabular data from PDFs to CSVs using Tabula and Pandas. Note that, Tabula only works with PDFs that are electronically created and if there are any scanned images, we'll need to use computer vision techniques to identify tables and extract them using tesseract. In this section, let's look at table extraction on electronic documents using Python.
PDF table to CSV with Python
This technique uses Tabla, a python-based framework that can extract tables from PDF documents. Make sure you have python> V3.6 installed on your machine or environment to follow along with this approach.
Step #1: Importing Tabula and Pandas
Import necessary libraries.
import tabula
Step #2: Loading PDF files into Python
We have used a PDF file from our local machine. To download this PDF and test it out, use the following link.
file = "table.pdf"
Step Three: Using Tabula to read PDFs
In this step, we'll use the read_pdf method from Tabula to read the PDF file, and we can also configure this with an additional parameter. In this example, we'll only be using the loaded table.pdf file and reading its first page. We can do this by setting the pages parameter to 1.
The read_pdf method returns the list of tables present on page one, here; as we have only one table, we access it by the 0th index of the list. Note that the data type of the returned table is as pandas data frame.
Step Four: Converting PDFs into CSV
Now that we have the table in a pandas data frame, it's easy to manipulate it and convert it into required formats like SQL table, CSV, TSV, and many more. To export this data into a CSV file, let's use the to_csv method.
table_one.to_csv("table_one.csv")
Following is how the data is represented in the CSV file:
Awesome, with just a few simple steps we were able to export the PDF table into CSV files, now let's talk a little about the workings behind Tabula.
Frameworks like Tabula and Camelot use techniques like Stream and Lattice to extract information from tables. These are basic algorithms that detect elements of tables and remove the text into a different format. To learn more about this, let's do a deep dive into this popular Lattice technique.
Compared to the Stream technique, Lattice is more deterministic in nature. Meaning it does not rely on guesses; it first parses through tables that have defined lines between cells. Next, it can automatically parse multiple tables present on a page.
This technique essentially works by looking at the shape of polygons and identifying the text inside the table cells. This would be simple if a PDF has a feature that can identify polygons. If it had, it would plausibly have a method to read what is inside of it. However, it does not
This is where we'll have to use a computer vision library like OpenCV to roughly perform the following steps:
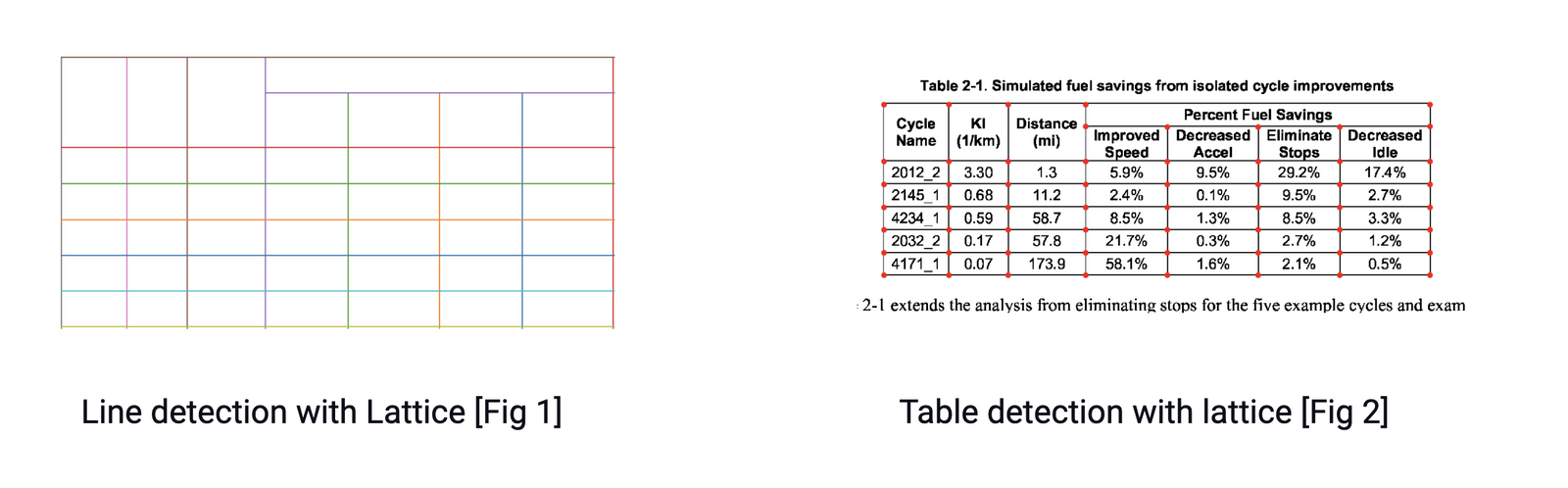
First, the line segments are detected
Next, the line intersections between lines are detected by looking at the intensity of the pixels of all lines. If a pixel of a line has more intensity than the rest of the pixel, it is part of two lines and, therefore, an intersection. As shown in figure 2.
The edges of the table are determined by looking at the intensity of the pixels of intersected lines. Here, all the pixels of a line are taken, and the most external lines represent the boundaries of the table
The image analysis is translated into the PDF coordinates, where the cells are determined. Lastly, the text is assigned to a cell based on its x and y coordinates.
Following is a screenshot of how tables are detected using frameworks like Tabula on PDF formats.
Need a free online OCR to extract and convert tables from PDFs, images to CSV? Check out Nanonets and build custom OCR models and extract/convert tables to CSVs for free!
PDF table to CSV with OCR and deep learning
We've seen how easy it is to convert PDF tables to CSVs when the documents are structured and electronically generated. But, that's not the case in all scenarios; sometimes, we encounter unstructured data where the text is placed inside PDFs or in different document regions. This makes it hard for normal frameworks like Tabula to read tables. Therefore, we utilize Computer Vision, OCR, and deep learning to identify, detect, extract, and export tables into necessary formats. Now, let's look at different techniques on how we can convert unstructured PDF tables into CSVs.
Computer Vision (CV) is a technology that trains computers to interpret and understand the visual world. In our case of extracting tables from PDFs, we'll be using computer vision to help us find the borders, edges, and cells to identify tables.
This is achieved by applying various filters, contours, and some mathematical operations to a PDF file. However, these techniques include some pre-processing steps on the data to perform accurately. To learn more about implementing CV algorithms for table extraction check out this blog post here.
Now, let's look at some of the popular deep learning architectures that can be utilised for exporting PDF tables into images.
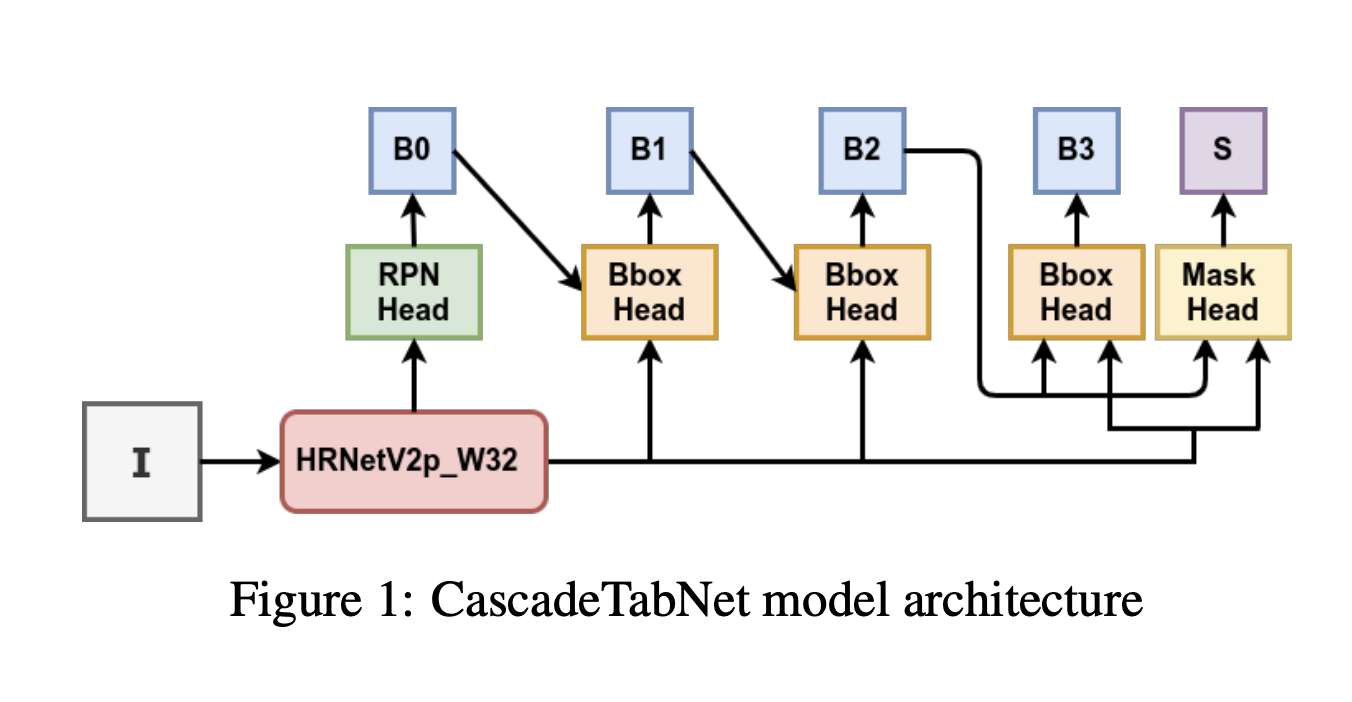
CascadeTabNet (An approach for an end to end table detection and structure recognition from image-based documents): Cascade Table Net is an OCR and deep learning-based architecture that has over 90% accuracy in identifying tables from image-based documents. The network utilises Cascade mask based CNN high-Resolution Network (Cascade mask R-CNN HRNet) as the core backend to identify tables from images. This same architecture had achieved 3rd rank in ICDAR 2019 post-competition results for table detection while attaining the best accuracy results for the ICDAR 2013 and TableBank dataset. Following is the screenshot of the architecture:
The Cascade R-CNN architecture is extended to the instance segmentation task by attaching a segmentation branch as done in the Mask R-CNN. This algorithm has also performed well irrespective of the borders of tables (with/without borders).
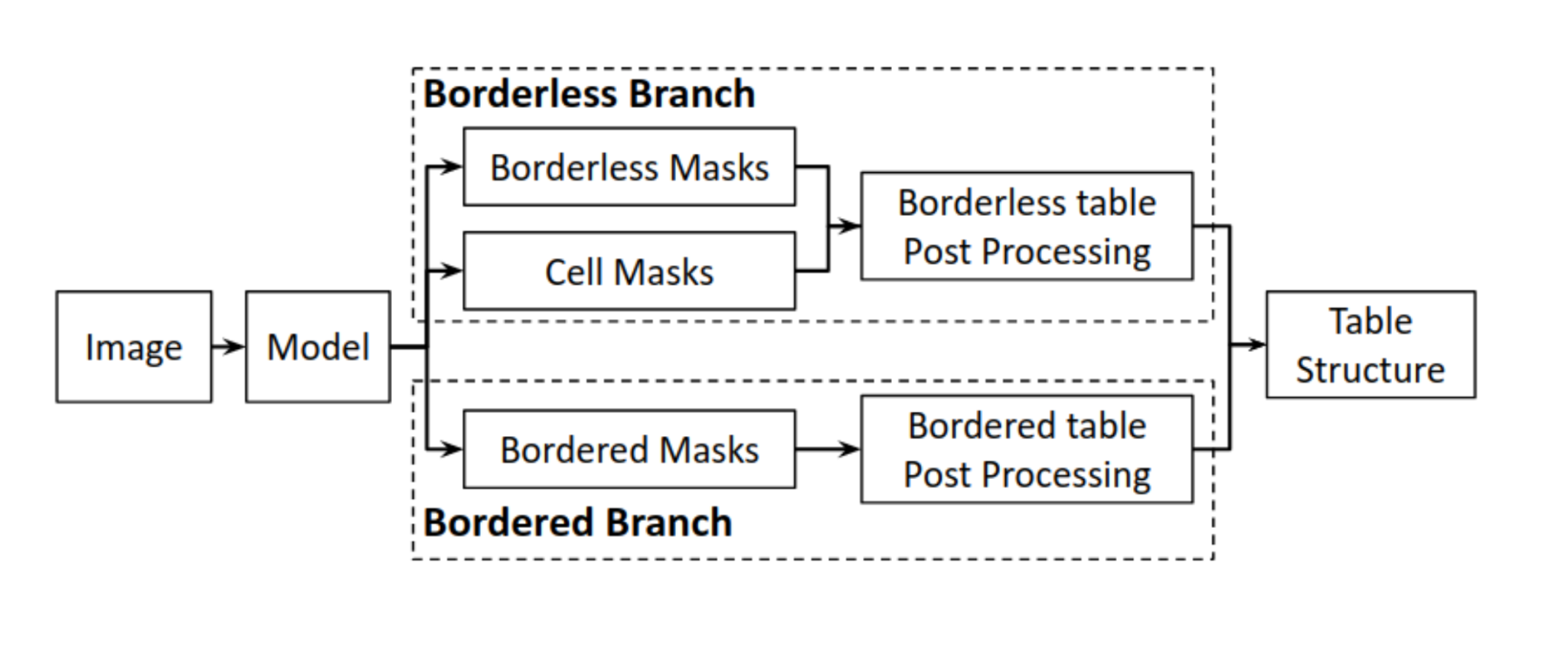
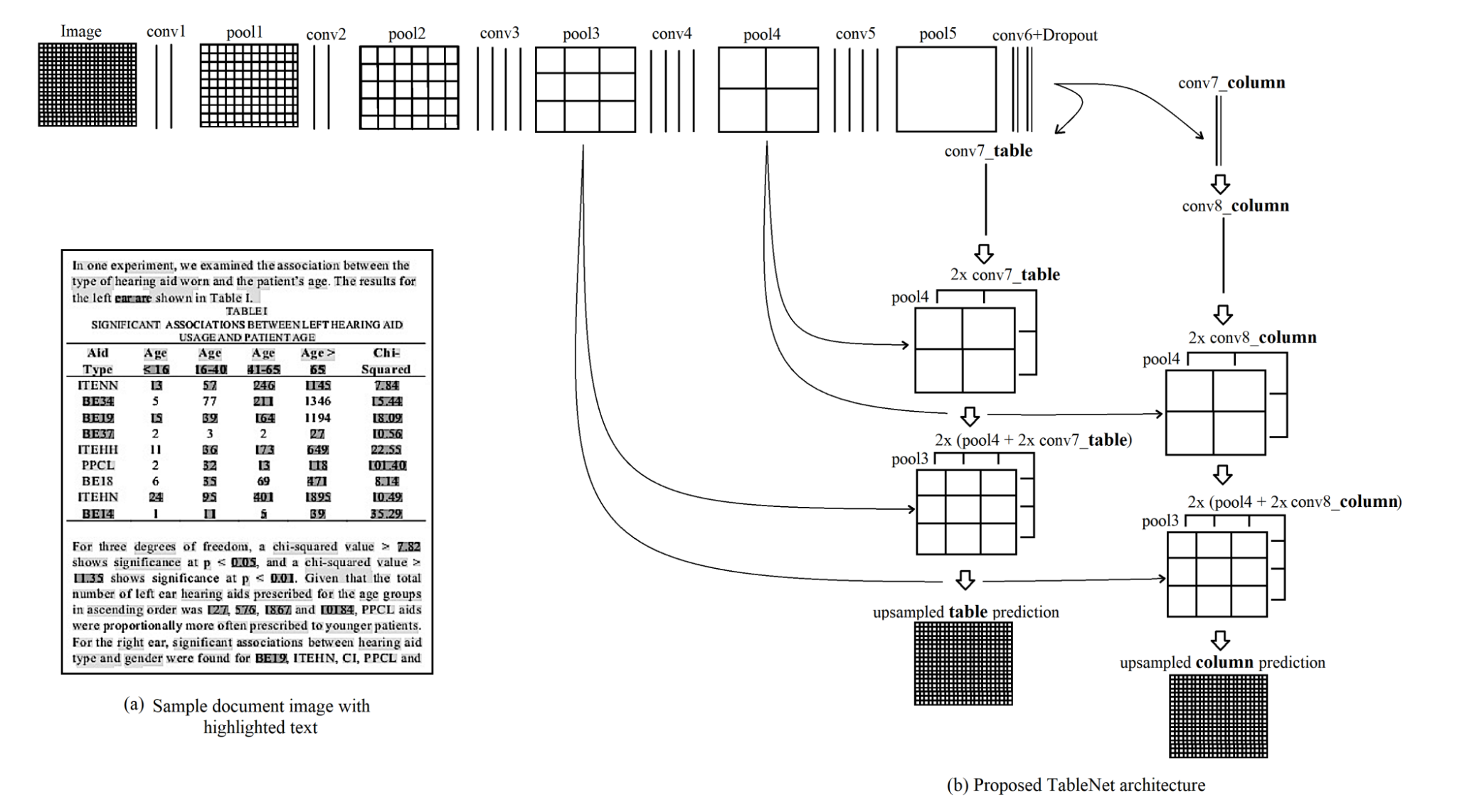
TableNet: TableNet is a popular deep learning-based algorithm that can perform table extraction on PDFs or any scanned information. This model has shown the state of the art results on ICDAR 2013 and Marmot datasets. The model utilizes a base network that is initialized with pre-trained VGG-19 features. Two decoder branches follow this, the first one performs segmentation of the table region, and the other is for segmentation of the columns within a table region. Subsequently, rule-based row extraction is employed to extract data in individual table cells. Following is the screenshot:
These are some of the techniques that are utilised for exporting PDF tables into CSV. However, when using deep learning one should employ solid pipelines for better results, as lots of pre and post-processing techniques should also be considered. In the next section, let's look at a simple automation workflow that helps build a pipeline for exporting PDF into CSV.
Need a free online OCR to extract and convert tables from PDFs, images to CSV? Check out Nanonets and build custom OCR models and extract/convert tables to CSVs for free!
PDF table to CSV automation workflow
Deep learning had a significant impact on document understanding, information extraction, and many more applications. Many things should be considered for use cases, such as table extraction, and solid pipelines have to be built to achieve state-of-the-art performance. This section will go through some of the steps and techniques needed to make solid neural networks to perform table extraction from a PDF file.
Data Collection: Deep-learning-based approaches are data-intensive and require large volumes of training data for learning effective representations. Unfortunately, there are very few datasets like Marmot, UW3, etc., for table detection, even containing only a few hundred images. However, for documents of complicated templates and layouts, we might have to collect our own datasets.
Data Preprocessing: This step is the most common thing for any machine learning or data-science-based problem. It mainly involves understanding the type of document we're working on. For example, say our goal is to export PDFs to Excel sheets. We'll have to make sure all the input data is consistent. These can be invoices, receipts, or any scanned information. But with consistency, deep learning models will be able to learn and understand the features with more accuracy.
Table Row-Column Annotations: After processing the documents, we'll have to generate annotations for all the pages in the document. These annotations are masks for tables and columns. Annotations help us to identify the tables, and its column regions from the image. Here, since an OCR like Tesseract already extracts all the other text inside the PDFs, only the text inside the tables has to be filtered out. Next, we'll have to define a collection of rows and multiple columns with these filtered words at a horizontal level. However, we'll also have to consider different segmentation rules depending upon the content of a column or line distinctions, and a row can span multiple lines.
Building a Model: The Model is the heart of the deep learning algorithm. It essentially involves designing and implementing a neural network. Usually, for datasets containing scanned copies, Convolutional Neural Networks are widely employed. However, building state-of-the-art models consist of a lot of experience and experimenting.
Post Processing and Exporting to CSV: After the model is trained, we can either deploy it locally or serve it as an API. For automation, APIs are strongly recommended, as most of the data is stored in the cloud. Therefore, using webhooks and intelligent automation software like Zapier and n8n, we can easily perform inference on PDF files. Additionally, libraries such as Pandas can be used to export the output into CSV based on required use-cases.
Need a free online OCR to extract and convert tables from PDFs, images to CSV? Check out Nanonets and build custom OCR models and extract/convert tables to CSVs for free!
Enter Nanonets
So far we've seen different methods for exporting PDF into CSVs, now let's look at how we can make this process easy by using Nanonets.
Nanonets is a cloud-based OCR that can help automate your manual data entry using AI. We'll have a dashboard where we can build/train our OCR models on our own data and export them in the form of JSON/CSV or any desired format. Here are some of the advantages of using Nanonets for PDF to CSV conversion.
Simple UI: Nanonets provides a simple and easy to use UI to train state of the art machine learning models. All we need to do is to upload the documents, annotate and train them without writing a single line of code inside the platform.
Add Custom Rules and Params: While training models on Nanonets, it provides us with the ease to customise the models. Using this, we can choose particular fields on our documents to extract. For example, if your business documents have 100 fields and you just want to extract around 30 fields, Nanonets can help you do that by just selecting the necessary fields on the model. This applies to all the documents by just configuring a single model.
High Accuracy, Less Processing Time: Nanonets is very well known for its state of the art models as it delivers more than 95% accuracy in identifying text, tables, and key-value pairs anywhere across the documents. All the extracted data can be evaluated on the GUI, in case of any errors, the correct value can be mentioned and the model rectifies itself in no time.
Post Processing Features: Nanonets provides the ability to add post-processing rules even after the model is trained. So in case if we miss anything using simple rules we can add additional information to the output without re-training the model.
Integrate Applications: Nanonets can easily integrate with any kind of data sources such as Excel, Google Sheets, and Databases using automation tools such as Zapier. Using these in our workflows will help us to run tasks in the background without any human intervention!
APIs and Webhooks: Nanonets provides a wide range of APIs with great supporting documentation. Using these we can easily utilise trained models inside web-based projects without worrying about any infrastructure. Additionally, webhooks can be utilised to power one-way data sharing based on triggers.


 is a cloud-based OCR that can help automate your manual data entry using AI. We'll have a dashboard where we can build/train our OCR models on our own data and export them in the form of JSON/CSV or any desired format. Here are some of the advantages of using Nanonets for PDF to CSV conversion.
is a cloud-based OCR that can help automate your manual data entry using AI. We'll have a dashboard where we can build/train our OCR models on our own data and export them in the form of JSON/CSV or any desired format. Here are some of the advantages of using Nanonets for PDF to CSV conversion.


No comments:
Post a Comment
Note: Only a member of this blog may post a comment.