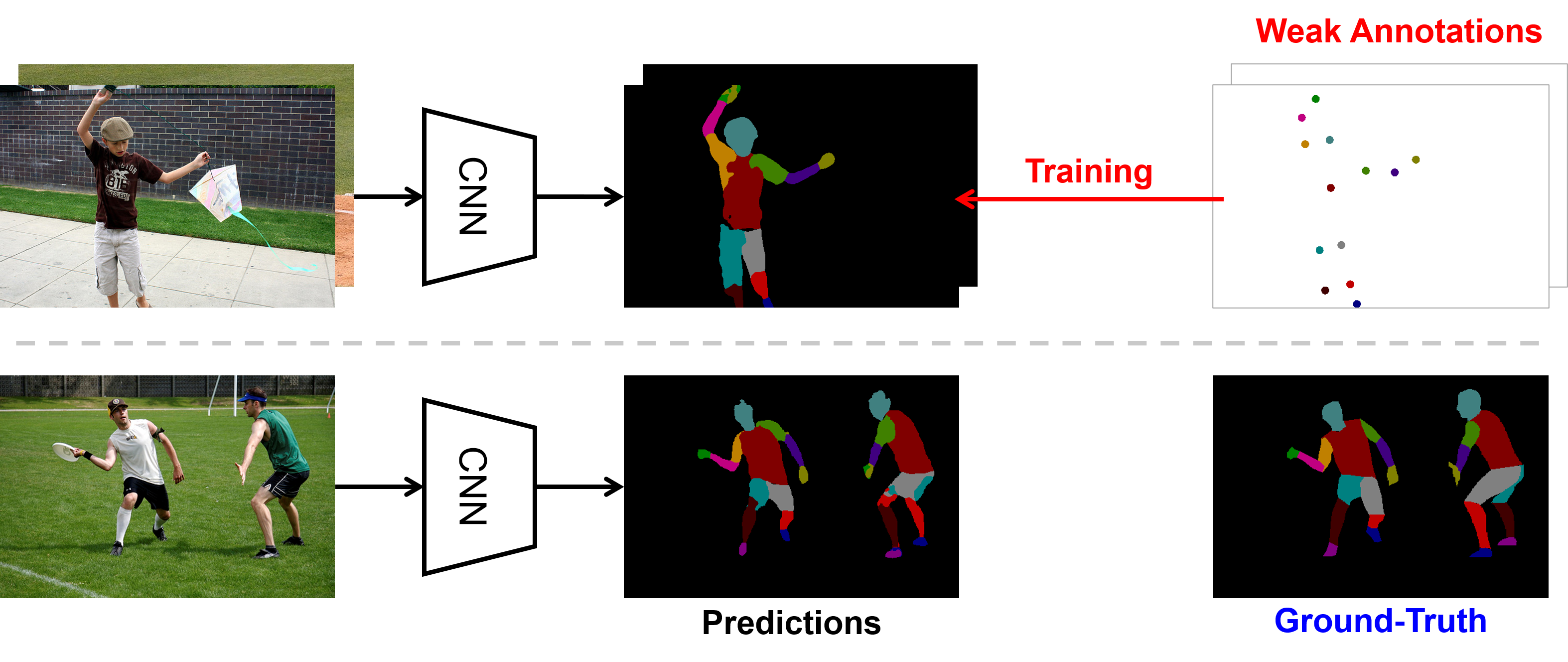
Matteo posted: " We consider a problem: Can a machine learn from a few labeled pixels to predict every pixel in a new image? This task is extremely challenging (see Fig. 1) as a single body part could contain visually distinctive areas (e.g. head consists of"
|
Subscribe to:
Post Comments (Atom)
-
With the Ultimate Summer Treat!͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ...
-
HTBS posted: " An anonymous parody of the famous mock announcement placed in the Sporting Times in 1882 following a shock ...
-
eddy posted: " 开学第二周,神兽们归位,开始了新学期的学习。突然之间,似乎增加了许多的事情。很快就感觉记忆力下降,视力下降,缺乏睡眠,临近burn-out的境界了。 调整了一阵,看了一部武侠小说,洗碗的时候放弃了"G...



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.