Matteo posted: " What is zonal OCR?In automated data extraction applications, one of the most useful developments in Optical Character Recognition (OCR) Technology has been the Zonal OCR, also called Template OCR and Zone OCR. Zonal OCR is useful when specific part"
In automated data extraction applications, one of the most useful developments in Optical Character Recognition (OCR) Technology has been the Zonal OCR, also called Template OCR and Zone OCR. Zonal OCR is useful when specific parts of a document must be preferentially or "zonally" extracted.
Table of Contents
How does Zonal OCR different from regular OCR ?
Regular OCR extracts all data from documents into accessible and manipulatable digital data. All matter present in the parent document is extracted with no differentiation by relevance or importance. Oftentimes, this kind of data extraction entails further manual extraction of relevant data from the ensemble of information indiscriminately gathered from the original document.
Zonal OCR, on the other hand, extracts only the important and specified data fields from a scanned document and stores the data in a structured database, for further automation or processing.
How does Zonal OCR software work?
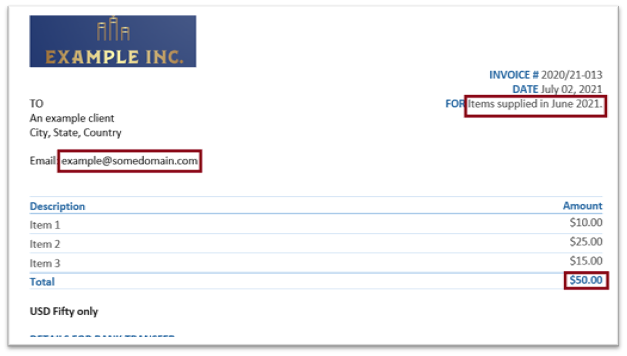
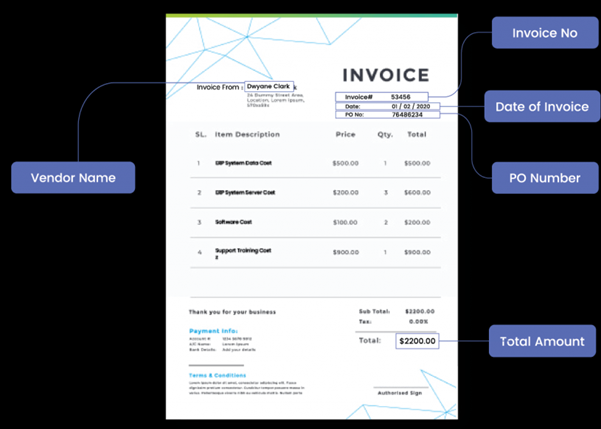
The zonal OCR software is trained to identify the structure and hierarchy of a document through code or API. The OCR engine then splits the document into zones that could correspond to a particular field. These zones are determined through design of appropriate OCR templates. These zones are usually location-based, as shown in the following figure, in which the user simply draws a square around data that must be extracted. Then, instead of reading the entire page as a single entity, the texts in the zones are identified and extracted as specified in the template. The zone OCR can be programmed to ignore graphical elements that need not be read, and this reduces the amount of information that needs to be parsed in order to pick out the needed data. This enhances data extraction speed and accuracy of the OCR engine.
The Zonal OCR system is trained by defining where specific data fields can be found inside a document. OpenCV, Tesseract, and Python are some zonal OCR systems that can be trained to pick out specific fields from a scanned document.
Different zonal OCR software work differently – some require that zones be in the same location in every scanned document while more advanced tools may be taught to look for the zones in different parts of the page.
Advantages of zonal OCR
Zonal OCRs allow capture of relevant data from paper documents, forms and e-documents that can be directly used in the next step of the automated business process with need for minimal human intervention. This "touchless processing" removes paper-centric processes and delivers better performance, scalability, and agility.
It avoids redundancy in data.
Zonal data extraction enables easy access to data to the entire team, or even company. This visibility can enhance productivity and reduce repetitive and wasteful effort.
Zonal data extraction can save valuable time otherwise wasted on manual data entry. According to McKinsey Digital, CEOs spend almost 20% of their time on work that could be automated, such as data entry, and a savings of 20% on time could lead to a commensurate savings in the bank; in businesses time is money after all.
Zonal OCR software can extract metadata from documents such as names, dates, and invoice numbers, which enables better data organization and management.
Advanced zonal OCR software can extract predetermined data into a tailored layout, enabling easy tracking and easy eyeball scanning for trends and issues.
Applications of zonal OCR?
Zone OCR software can be used to extract useful information from any kind of document, when properly trained. Some areas that are benefited by zonal OCR are:
Invoice digitization: An invoice/bill is made of various fields including name, address, dates, products, cost etc. placed at different locations. A well-trained Zonal OCR algorithm can extract all of this data separately and store it as a structured database.
Purchase Order digitization: Much like the invoice, a purchase order (and receipt) also contains useful fields that need to be stored in a central database of a company. Zonal OCR can help with keeping track of purchase orders and receipts.
ID card digitization: Documents such as IDs are constantly submitted for various processes. The process of manual ID validation and data entry is time consuming and prone to errors. Zonal OCR can hasten the data entry process in applications that require use of id cards and such other documents.
Text detection in images and objects: Capturing a meter reading, or a road sign, or the license plate of a speeding vehicle requires advanced zonal OCR software that can pick up text from blurry or fast-moving images.
Other applications of zonal OCR tools include bank statement processing, operating protocol processing, customer database maintenance, bills processing, etc.
Drawbacks of Zonal OCR
Less sophisticated Zonal OCRs could fail in extracting data from semi-structured documents, in which the fields to be extracted are not in the same position in all the documents.
Zonal OCRs are incapable of extracting text from complex data fields, such as multi-line postal addresses.
Zonal OCRs also struggle to extract sequential data fields (e.g. continuing product numbers in the same invoice or receipt).
More advanced AI-based OCR tools such as Nanonets that use machine learning & image processing techniques can overcome some of these issues.
AI based OCR with Nanonets
Nanonets is an OCR software that leverages AI & ML capabilities to automatically extract unstructured/structured data from PDF documents, images and scanned files. Unlike traditional OCR solutions, Nanonets doesn't require separate rules and templates for each new document type.
Nanonets demo
Relying on AI-driven cognitive intelligence, Nanonets can handle semi-structured and even unseen document types while improving over time. The Nanonets algorithm & OCR models learn continuously. They can be trained or retrained multiple times and are very customizable. You can also customize the output, to only extract specific table or data entries of your interest.
While offering a great API & documentation for developers, the software is also ideal for organizations with no in-house team of developers.
It is fast, accurate, easy to use, allows users to build custom OCR models from scratch and has some neat Zapier integrations. Digitize documents, extract tables or data-fields, and integrate with your everyday apps via APIs in a simple, intuitive interface.
Check out these inspiring customer success stories that showcase how Nanonets helped businesses grow quickly and be more productive.
The benefits of using Nanonets over other automated OCR software go far beyond cost savings, accuracy and scale. Nanonets additionally provides unique benefits that place it far ahead of the competition:




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.